WP_HTML_Tag_Processor is a powerful new tool that has been a part of WordPress since Version 6.2. It provides developers with a streamlined way to adjust HTML tag attributes, and it looks like it’s just the beginning of a set of tools coming to the WordPress ecosystem. This article addresses using WP_HTML_Tag_Processor, benefits, and what’s missing.
Should Developers Be Using WP_HTML_Tag_Processor?
Let’s all be clear that even experienced developers are not quite fond of using regular expressions. They are not readable and friendly, and it takes a while to get used to them if you haven’t used them in a while.
For example, what if you wanted to create a function that adds an extra-strong class to the existing <b> and <strong> tags in post content? Below, we’ll compare doing so using Regex vs using WP_HTML_Tag_Processor.
WP_HTML_Tag_Processor vs Regex
Here’s the example content:
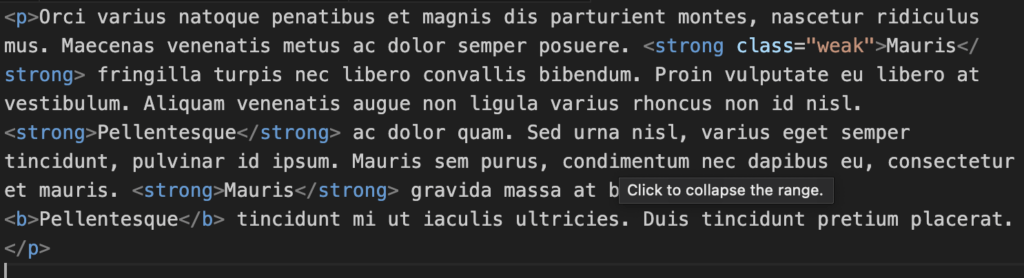
This is how the function looks using Regex:
That’s a lot of code for something that we might consider very simple. How hard does it need to be to add a class to a couple of tags, right?
Now, let’s look at what happens when using the WP_HTML_Tag_Processor approach:
This is way more readable. You can see there’s a while, then you loop through the elements, and if you find what you’re looking for ( a <b> or a <strong> tag ), then you just go for it and add the class.
Here’s the result:

As we can see, the extra-strong class was properly added, and even the existing class was considered.
This is just one quick example of how using WP_HTML_Tag_Processor can make our lives easier. There are other things that we can do with it, such as:
- Updating properties before sending the content to the DOM. For example, adding properties like lazy-loading or removing inline CSS elements.
- Operations are safe by default. There’s no need to escape the content before or after.
- You can set an attribute value without checking if it exists; it won’t be duplicated.
- You can find tags by name and/or class name. See the example below.
Everything looks great, but what about performance?
Performance matters. I took the liberty of testing the performance against our previous Regex function and through the XQuery function as well.
Remember the Regex function:
Now, here’s the XQuery function:
I ran this through a WP installation with more than 8,000 posts, and these are the results:
| WP_HTML_Tag_Processor | 11.9 seconds |
| XQuery | 2.29 seconds |
| Regex function | 0.9 seconds |
That makes you think. Is its readability enough to compensate for the lack of performance? Again, this is an isolated case, and maybe this might be fit for smaller use cases and not to be used to perform large operations.
What’s Missing from WP_HTML_Tag_Processor?
Since this is a new tool, there are a couple of features that we wish we had but are not still available in the API, such as:
- You can’t find nested tags or updated tag’s innerHTML or text.
- You can’t delete or add new tags
- You can’t read the content between two tags.
- Even though you can confirm if a tag is self-closing, you can’t match an opening tag with a closing tag.
Some of these features might never be available due to the nature of this API, and some of them can decrease its performance substantially, so those constraints help the API remain efficient.
Are you planning to use the WP_HTML_Tag_Processor in the future? Let us know down below in the comment section.