Here at WebDevStudios, we use a variation of the Git workflow known as Git Flow.
One of the benefits of using Git is quick and easy branching and merging without conflicts. Git Flow makes extensive use of branches to ensure that work that you are currently developing doesn’t break things that someone else is working on.
A lot has been written about Git Flow–the first time I learned about it was on Jeff Kreeftmeijer’s blog a couple years ago, but it was originally devised in 2010 by Vincent Dreissen. Since then, Git Flow has been added to popular Git GUI clients like SourceTree and Tower.
For those of you not familiar with Git Flow, I’m not going to go in depth about how it works, but I’ll walk through a really simple workflow example and how we use it at WDS.
Git Flow Workflow
We start off with two branches–at WDS these are prod and master (these are most often the master and develop branches in typical Git Flow environments). Prod is what will ultimately get pushed to a client’s site and master gets deployed to our lab server and is where most of the development happens.
Both prod and master need to stay clean–no broken or in-progress code should be pushed to those branches. To make sure this is the case, Git Flow introduces branch trees for features, hotfixes, and releases (we don’t use the latter). When I start working on a new component for a site, I create a new feature branch, feature/my_cool_feature. I can push this feature branch to the repo so other people can work on it while it’s still in development. When I’m done, my feature branch gets merged into master, and I can start working on a new feature.
When the project is in a production-ready state, master gets merged into prod and then the QA process starts. If there’s a problem with a component I built, I can create a hotfix branch, hotfix/fix_my_cool_feature. Hotfix branches are branched off prod and when they are done and tested, hotfix branches get merged into both prod and master.
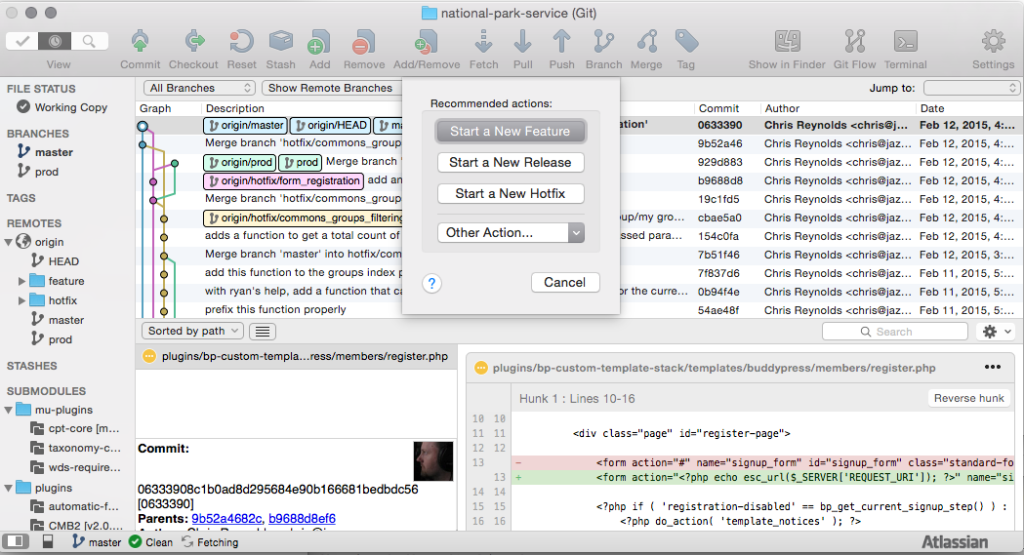
Using SourceTree (or Tower), the branching and merging happens automagically; I click a Git Flow button and, in the window that pops up, tell it that I want to create a feature, hotfix or release branch, and my client will take care of creating the branch. When I’m done, I click the Git Flow button again and click “Finish Current”, and my client takes care of merging.
(Important note: Your local master and prod branches need to be current for the merges to work, but Git will bail if you’re behind the origin on either of those and not let you merge your feature, hotfix, or release branches until you’ve sorted that out.)
You don’t need to use the fancy buttons in a GUI Git client or even use the Git Flow commandline functions to use the workflow. You can just create the branches and merge manually if you don’t have a Git client that has the fancy, built-in functionality, or don’t want to use the commandline tools. I used the Git Flow workflow for at least a year or two before I even tried the built-in features in Sourcetree.
Using stashes
That’s great, but what happens when you start working on a new feature or a bugfix and oops! You realize halfway into it that you’re still working off of master? Time to copy all your code, save it into a text file or a Gist, and then reset the file to the last commit so you can make a new branch, right?
Wrong! This is where stashes come in!
Now, before you yell at me: Yes, you can absolutely create a branch off master (or even prod) when your files have changed and don’t match what’s on the origin repo. Even using Git Flow and creating a feature branch won’t give you problems. However, if you try to create a hotfix branch, and your local doesn’t match what’s on the origin, it will yell at you and tell you you have uncommitted changes.
Stashing is simple. From the command line it’s just git stash. Not only will running git stash save your changes, it will return your local to a working environment that matches the origin. Then you can create your branch and apply your changes with git stash apply to your branch. No muss, no fuss.
You can create as many stashes as you want and you can delete them at any time. They only exist in your local repository and never get pushed to origin. It’s basically the same as copying just the code that’s changed to a text file somewhere so you can come back to it later, except that you’re making Git do all the hard work of actually copying said code.
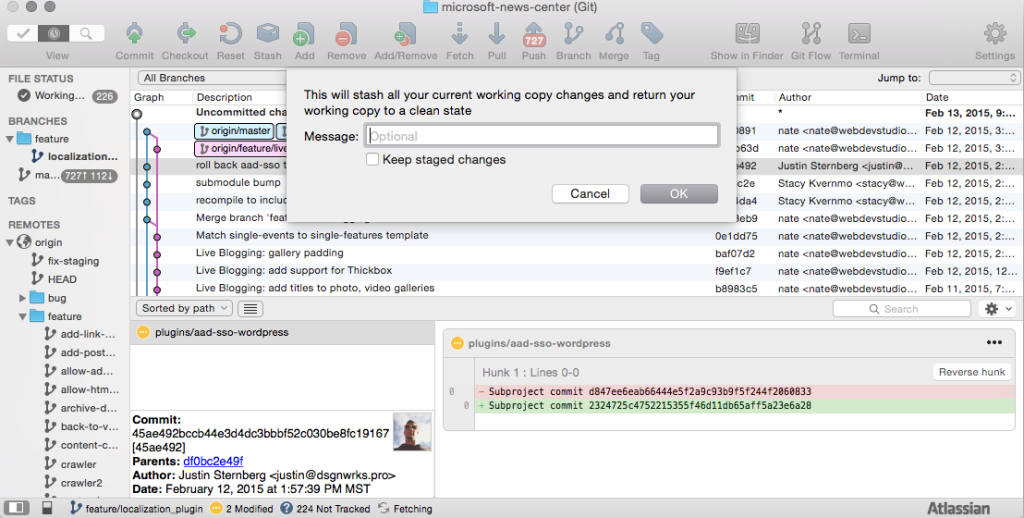
In Sourcetree, you can create stashes from the Repository dropdown or with Shift + ⌘ + S on Mac clients. You can choose to give your stash a name so you remember it later, and then click okay. Your changes are saved in the stash and your repository is back to the unmodified version that matches the last time you pulled from the origin repository.
I use stashes all the time because I’m flipping between branches a lot and, especially when we’re fixing bugs in QA, my branches are often very small and specific to a particular issue. When I’m done with that and pushing up the fix, I’m probably already looking at the next task, which then leads to me starting to work on that task, and I find myself forgetting to create a hotfix branch before working on a fix more often than not.
Stashes save a lot of extra headache and time wasted and they are completely safe, because your stashed changes aren’t pushed to the origin repository until you choose to push them. I find I use them a lot more since we’ve started using a modified Git Flow workflow than I ever did before using Git Flow exclusively. It’s really easy to just say “well, I’m going to just push this one thing and then create a branch” but stashes make it so you don’t need to do that.
Have your own great uses for Git stashes? I’d love to hear about them in the comments!
Nice post. Check out my GitFlow for Visual Studio extension if you are using VS:
http://geekswithblogs.net/jakob/archive/2015/02/12/introducing-gitflow-for-visual-studio.aspx
Hi, I’m newbie to Git/GitFlow. How can I commit my changes using Visual Studio 2015. Could you please elaborate the steps for commit the changes to server and get latest to local. I don’t have any experience on git. Can you please share the steps to do (sing GUI not commands).
Thank you sir.
Hi, Kumaranan. The previous commenter, Jakob, mentions and links to his blog post on GitFlow for Visual Studio. We recommend you check out his blog post here: http://blog.ehn.nu/2015/02/introducing-gitflow-for-visual-studio/