We’ve mentioned it before, but at WebDevStudios, we use git flow–a specific git workflow first proposed five years ago, though the original author, Vincent Driessen, says he had been using it for a year before posting about it. Git Flow works best when you are developing a product that has definitive releases, but this gets really gray when you have a handoff process where you build a complete site and then give it to a client. We’re working on developing a Git Flow process that adapts Git Flow for use in client work.
First, let’s review how Git Flow works.
Main Git Flow Branches
It all starts with two main branches: master (which is the stable version of the software) and develop (which is where all the development happens). The main idea here is that develop is constantly changing as new things are added, and when features are completed, they are merged into master.
In this scenario, develop is always going to reflect what’s going into the next production release.
Supporting Branches
There are also three different sets of supporting branches.
- feature branches are for new features being developed for future versions of the software. When creating feature branches, a hierarchy is added by prefixing the branch with
feature/, for examplefeature/my-cool-feature. features branch from the develop branch. - release branches are used to organize features and fixes going into the next major software release. Like feature branches, they have a hierarchy added, like
release/1.0. Like features, releases usually branch off develop. - hotfix branches work a little different. Hotfixes are for when there’s an issue in the production software out in the wild and you need to fix it now and make sure it doesn’t get reintroduced. These branch from master (where the bug is) and merge into both master and develop, to make sure that the bug doesn’t come back when the next version is released.
A theoretical workflow might look like this (note: all images in this section are taken from Vincent’s post):
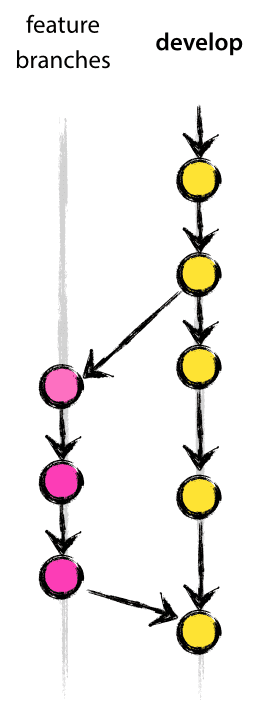 The current production version of our software is 1.0. We would like to start development on the next major release, 1.1. At this stage, master and develop are at the same state; we’ll assume we just barely shipped the 1.0 version. So we start by creating a release branch for our next version:
The current production version of our software is 1.0. We would like to start development on the next major release, 1.1. At this stage, master and develop are at the same state; we’ll assume we just barely shipped the 1.0 version. So we start by creating a release branch for our next version: release/1.1.
When I start on a new feature for the 1.1 version, I create a new feature branch off of develop, build my feature out, and then merge it into develop. When develop is in a state where it’s getting ready for release, develop merges into release. The idea behind the release branch is it serves as a place for final changes, bugfixes and other minor changes that need to be taken care of before the next version is shipped. Those bugfixes and changes would then get merged into develop because, at this point, we’ve switched to committing directly to the release branch.
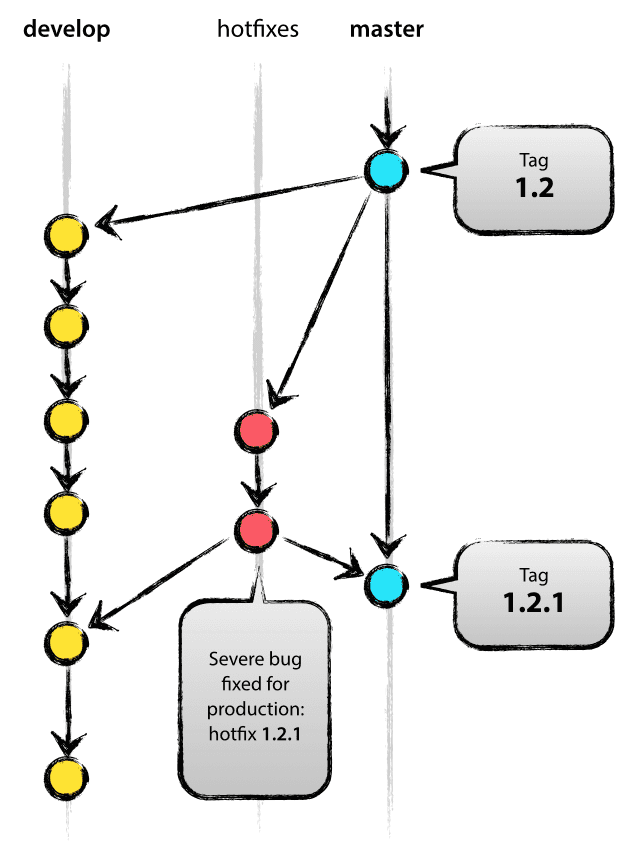 Now, let’s say, as we’re working on 1.1, something comes up–something’s broken and we need to fix it ASAP. I’ll create a hotfix branch off master,
Now, let’s say, as we’re working on 1.1, something comes up–something’s broken and we need to fix it ASAP. I’ll create a hotfix branch off master, hotfix/some-bug, finish that, and then merge the result into develop and master. What gets merged into master becomes the 1.0.1 release, and we create a tag for that version because we need to ship it before the 1.1 release is done. Merging it into develop means that we can be sure that the bug isn’t reintroduced once the new features being worked on in the 1.1 release get merged into master.
All of these branches can (and probably will) exist concurrently as different people are working on different elements. If I want Camden to look at something on my feature branch, I can ask him to check out which branch I’m working on and he’ll pull that down to his local, test it, and maybe commit some changes of his own to that branch which I can pull down when they’re ready. We can both be working on the same branch simultaneously, too, although before we’re able to push anything, we’d need to make sure our working copy has any changes that were pushed to the repository.
Putting all that together, you have something that looks like this:
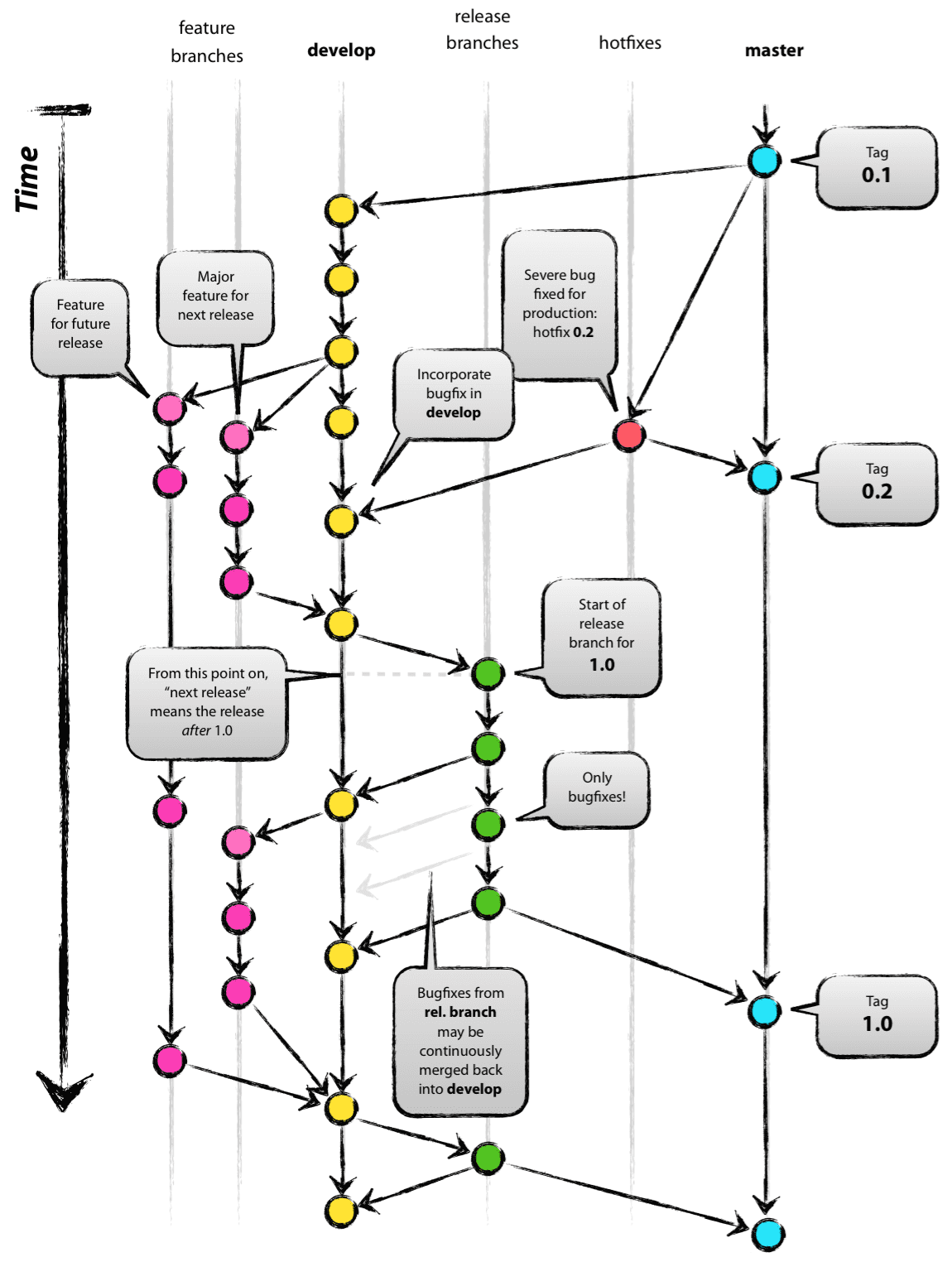
WDS GitFlow
On client projects, the release branch loses importance. So do tags (although maintaining an archive of “versions” is helpful for backups). Our process has evolved out of this Git Flow model, and it starts off similarly, but has some distinct differences.
Pre-launch
Before the site is launched, there’s really only one main branch and two supporting branches. Our main branch is master, because when you set up a Git repo, that’s the initial branch you have. But our master branch is our development branch. Our production branch is prod, not master. The supporting branches we use are feature, which branches from master and is used primarily for functionality additions (largely stuff handled by the back-end developers) and theme, which also branches off master, and is used for things that go into the theme for the site. At this point, our Git process looks like this:
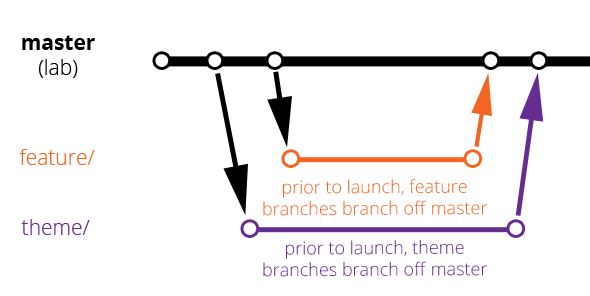
We also have deployments set up, so that commits to master are auto-deployed to a live lab server we run and test on in addition to our local environments. When the site gets ready to launch, we create a the prod branch off the finished and stable master branch and that gets deployed to the production environment. This makes deployments to production more intentional; in order to push to the production site, you need to check out the prod branch and deliberately push your changes. This makes it so there should be no surprise when code is on prod.
Once on the production environment, we go into final QA mode. We will have QA’d things on our lab server, of course, but inevitably there will be slight differences in environments from our lab server and the production server or things won’t work quite the way they were expected when the client is testing. At this point we use the hotfix branches to address any issues that are in existence in production.

When all remaining issues are taken care of, the site is either handed off to the client or we get ready to start work on a Phase II of the project. And this is where our new Git Flow model really kicks in.
Release as a Staging Environment
The guiding theory behind the revised Git Flow model is to use the release branches as a staging environment, ideally with a staging server that mirrors the production environment. As an added component, we’ve most recently started experimenting with release sprints. These essentially act like releases in the existing Git Flow model, where you are pushing toward a specific version, but instead of development coming off of develop (or, for us, master), our feature and theme branches split off the release. master (our development branch) is downgraded to, primarily, a testbed that has the added bonus of deploying to a lab server. Branches are kept clean from each other by coming off the release branch for the sprint we are working on and only getting merged back into that release when the feature is done done and has been tested to be working on master.
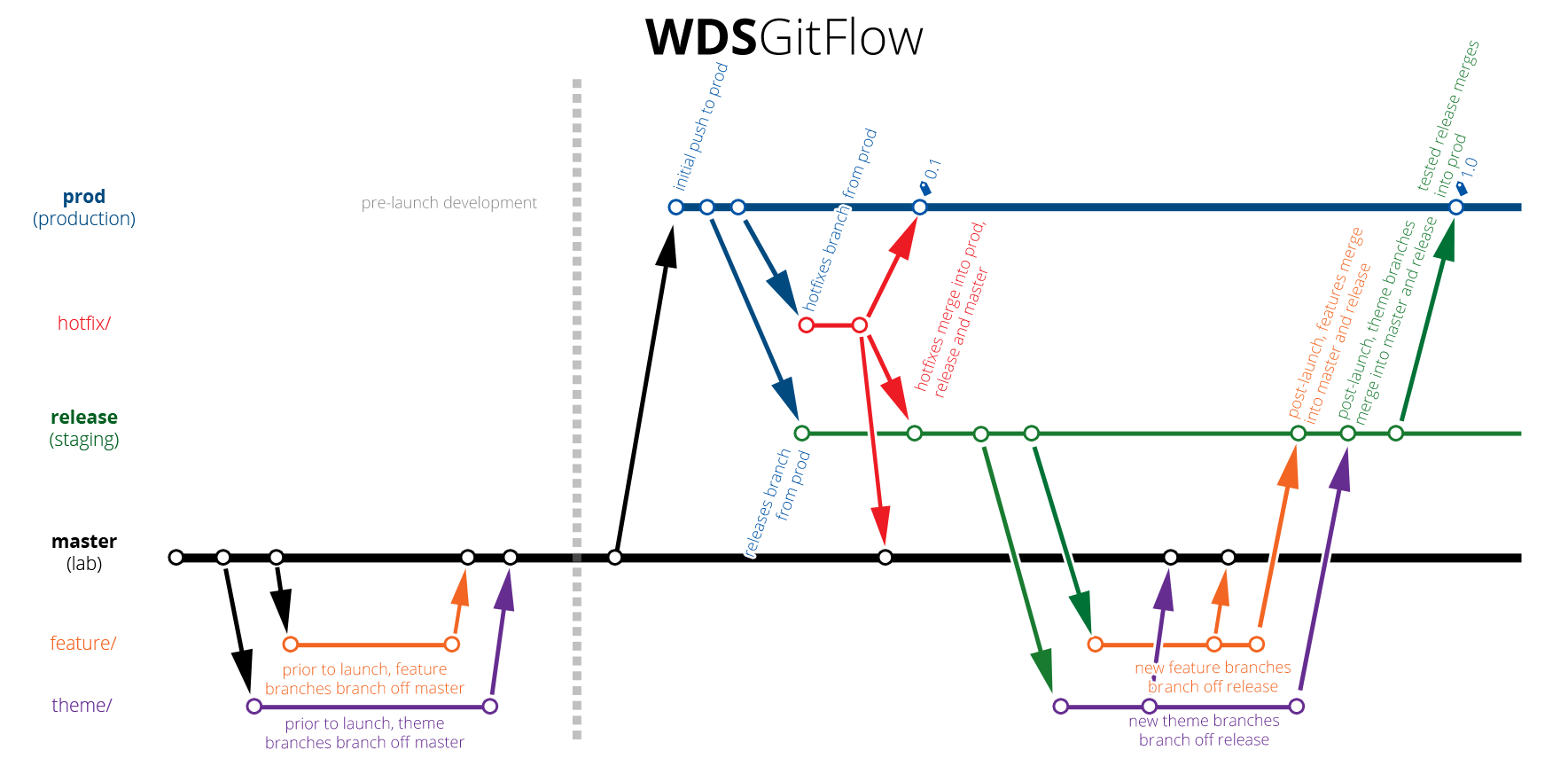
When that particular release sprint is done, it is merged into prod and we start working on the next sprint. It’s important to note that, at any given time, we could have devs working on different release sprints and that these sprints could be happening independent of each other. Unless we’re making changes that affect specific components from other sprints or feature branches, code changes are isolated and don’t end up in merge conflicts and features are more or less grouped to go into a specific sprint to prevent the same file being changed by different people at the same time on different releases.
If a bug is identified after we’ve started working on a release, the hotfix will be merged into any release branches there might be as well as going into master and prod.
Using this model, if I was building a feature, I would start by creating a new feature branch off the release branch–something like feature/my-new-feature. I would push my code to my feature branch. When I was done, I would merge feature/my-new-feature into master which gets deployed to the development server and is available for testing. If that feature tests good, my feature branch is merged directly into the release branch; it already exists in the master branch. It’s important to note that the code doesn’t get merged into the release until after it’s been tested on the development server.
When a sprint release branch is merged into prod, we’ll tag it (we’re still working out a naming convention, since version numbers aren’t as significant as dates) to create an archive that’s easy to roll back to if there’s ever a problem later.
Advantages of using this model
Having a dedicated staging environment is a good thing. Once a site is live, you don’t want to push code to it and potentially break it. But your development environment might not match the production environment. This is especially true if, as is often the case for us, you are maintaining your own development server, but the production server is running on a different host with a different environment. Maybe the production environment is a Windows Azure server, but your development server is running Linux. That makes having a staging environment to make sure that all your code works in Azure pretty important.
This workflow builds the staging server into the process so you have a place to push code that’s ready to go while giving you a failsafe in case there were issues that weren’t accounted for in testing or if there are environmental differences between the production server and the development server.
For freelancers and agencies, the traditional Git Flow workflow often doesn’t make as much sense because you aren’t producing a single “product”. You’re often producing multiple products–a combination of custom plugins, themes, and possibly even specific, curated plugins that your specific custom functionality extends. But that doesn’t mean that Git Flow shouldn’t be used in those cases. Instead, adapting the workflow to what works best in your situation can be incredibly valuable and prevent issues down the road.
What do you think? Are you using Git Flow? What is your typical workflow for client project development? Let us know in the comments!
Great article, Chris! Very interesting.
For WordPress, I don’t really use tags, since the version number is already “hardcoded” in the plugin or theme. I normally commit with the version number as commit message right before release. That’s my tag I guess.
For stuff I push up to GitHub (plugins and themes, specifically), I’ll always use tags. The benefit there is it will automatically create a release archive for the project (e.g. https://github.com/jazzsequence/book-review-library/releases). For client work, obviously it’s a different thing, but we’ve had issues where we’ve needed to restore the production site back to a previous commit, and IMO finding the right tag is easier than digging through the commit history.
On the other hand, I tend to move my tags around a lot and delete/readd them when I end up finding a problem that needs to be fixed in that version, so I totally empathize with not doing it. 🙂
After all, creating a tag is near-zero effort, so why not! 🙂
how does your team handle multiple theme development?
let’s say Developer 1 has
theme/demo1 branch
and developer 2
theme/demo2 branch
should theme/demo1 branch needed to deploy to prod first before merging the
the,e/demo2 in master?